プライバシー保護連合学習技術「DeepProtect」を活用した
銀行の不正口座検知の実証実験を実施し、検知精度向上を確認
ポイント
-
銀行4行と連携し、プライバシー保護連合学習技術「DeepProtect」を活用した不正口座検知の実証実験を実施
-
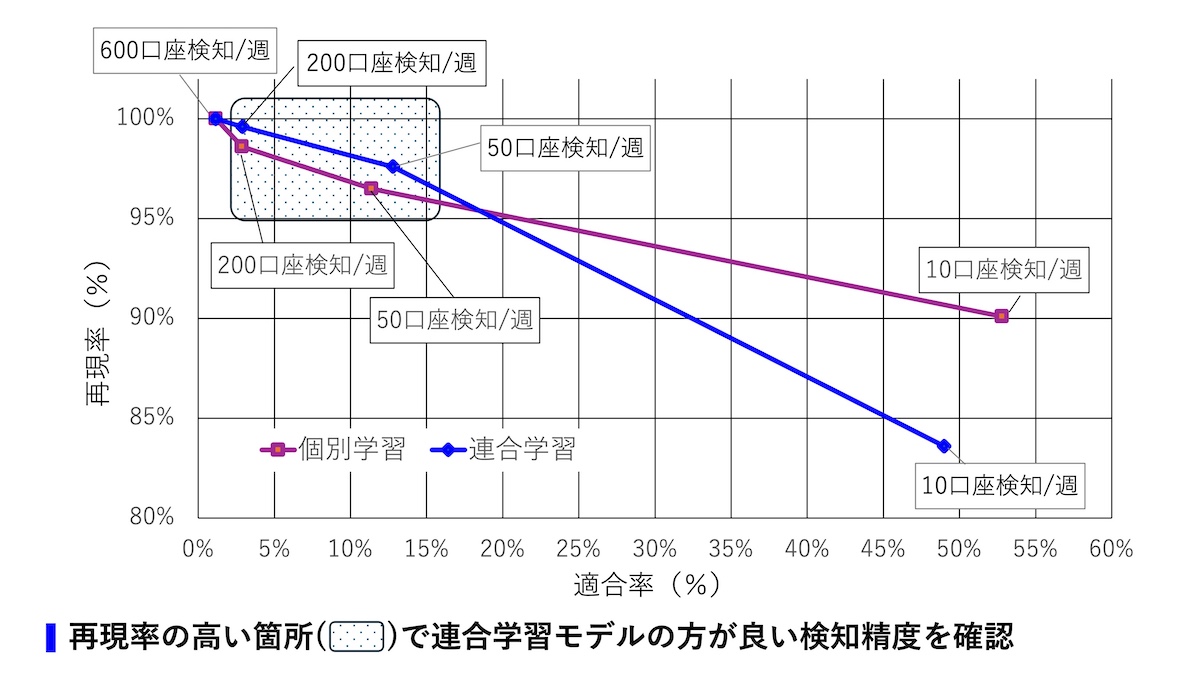
個別学習モデルと連合学習モデルを組み合わせたアンサンブル学習を適用し、不正口座検知の精度向上を確認
-
不正取引モニタリング業務での実運用に向け、現行システム(AMLシステム)と並行運用の可能性を検討
背景
今回の成果
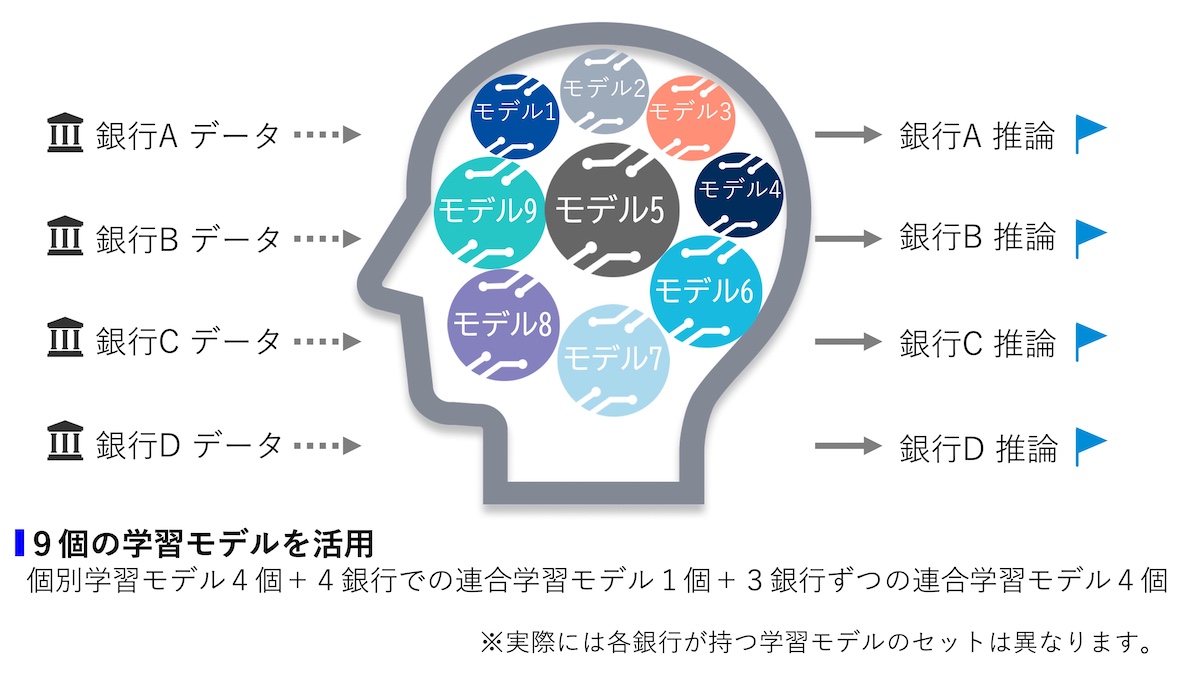
今後の展望
各機関の役割分担
- NICT:
- 全体マネジメント、DeepProtect技術の提供、実証実験結果報告及びヒアリング調査のためのワークショップ開催
- 神戸大学:
- 実証実験環境の開発と性能評価、DeepProtectの敵対的サンプル攻撃等への耐性向上、不正送金検知特徴量と不正判定基準の標準化
- EAGLYS:
- DeepProtectの継続学習化、モジュールの開発、人間系フィードバックを容易とする支援ツールの開発
関連する過去のNICTのプレスリリース
- 2022年3月10日 プライバシー保護連合学習技術を活用した不正送金検知の実証実験を実施
https://www.nict.go.jp/press/2022/03/10-1.html - 2020年5月19日 プライバシー保護深層学習技術を活用した不正送金検知の実証実験において金融機関5行との連携を開始
https://www.nict.go.jp/press/2020/05/19-1.html - 2019年2月1日 プライバシー保護深層学習技術で 不正送金の検知精度向上に向けた実証実験を開始
https://www.nict.go.jp/press/2019/02/01-2.html
用語解説
プライバシー保護連合学習技術「DeepProtect」
連合学習技術に暗号技術を融合することによって、NICTが独自に開発したプライバシー保護連合学習技術のこと。まず、各組織で持つデータを基に深層学習を行う際に、学習中のパラメータ(勾配情報)を暗号化して中央サーバに送り、中央サーバでは、暗号化したまま学習モデルのパラメータ(重み)の更新を行う。次に、更新されたこの学習モデルのパラメータを各組織においてダウンロードすることで、より精度の高い分析が可能になる。DeepProtectは、各組織から中央サーバにデータそのものを送ることなく、学習中のパラメータのみを暗号化して送信するが、このパラメータは、複数のデータを集計した統計情報とすることによって個人を識別できない状態にすることが可能であり、さらに、暗号化を施すため、データの外部への漏えいを防ぐことができる。
本技術により、パーソナルデータのような機密性の高いデータを外部に開示することなく、複数組織で連携して多くのデータを基にした深層学習が可能となる。
本技術は、下記ジャーナルに採択・掲載されている。
L. T. Phong, Y. Aono, T. Hayashi, L. Wang, and S. Moriai, "Privacy-Preserving Deep Learning via Additively Homomorphic Encryption", IEEE Transactions on Information Forensics and Security, Vol.13, No.5, pp.1333-1345, 2018.
L. T. Phong and T. T. Phuong, "Privacy-Preserving Deep Learning via Weight Transmission", IEEE Transactions on Information Forensics and Security, Vol.14, No.11, pp 3003-3015, 2019.
本技術は、下記動画でも紹介している。
『NICTステーション ~DeepProtect~』
https://youtu.be/CpA9OD5vUIM
元の記事へ

検知精度
今回の実証実験ではモデル評価の指標として、適合率(p)、再現率(r)、平均適合率(AP)を使用した。平均適合率はモデルの全体的な性能を表す指標であり、Precision-Recall曲線の下側の面積を計算することで求められる。
元の記事へ
アンサンブル学習 アンサンブル学習は、一般的には複数の機械学習モデルを組み合わせて、精度の高い推論を導出する機械学習手法。当実証実験では各銀行の個別学習モデルと複数の連合学習モデルを組み合わせることで、データ項目のばらつきがあっても情報量を余すことなく利用するアプローチを適用した。 元の記事へ
適合率 モデルが「不正」と予測したデータのうち、実際に「不正」であった割合を示す指標。適合率が高いほど、誤検出が少なく、正確に予想できていることを意味する。適合率は、スパムメールの検出など「誤検出を減らすことが重要なケース」で重視される。 元の記事へ
再現率 モデルが実際に「不正」であるデータのうち、どれだけ正しく「不正」と予想できたかを示す指標。再現率が高いほど、取りこぼしなく正しく検知できていることを意味する。再現率は、不正検出など「取りこぼしを減らすことが重要なケース」で重視される。 元の記事へ
AMLシステム AML(アンチ・マネー・ローンダリング)システムとは、金融機関における資金の流れを常に監視し、不正が疑われる取引があれば自動で検出するソフトウェアのことである。近年、日本におけるマネー・ローンダリング及びテロ資金供与対策では、取引時確認や疑わしい取引の検知・届出といった様々な局面で、AI、ブロックチェーン、RPA(ロボティック・プロセス・オートメーション:人工知能等を活用した定型的作業の自動化)といった新技術が導入され、実効性向上に活用されている。 元の記事へ
銀行の不正取引検知における不均衡データ問題 銀行の顧客口座の大多数は通常取引を行う正常口座であり、サンプルとして扱える不正取引を行う口座は極端に少数である。本研究ではデータ生成源モデルの推定とそれに基づくデータ生成を行い、合成データを訓練データに追加して学習することで性能改善を確認した。 元の記事へ
敵対的サンプル攻撃 AIの入力に摂動を与えて意図的にAIに誤判定させる攻撃。不正取引検知においては銀行側が設置した不正検知AIが顧客の口座取引を監視する中で、犯罪者による不正取引を見逃すように仕向けること。本研究では不正取引データの合成と敵対的攻撃アルゴリズムを組み合わせて、AIに検知されない不正取引を探索した。 元の記事へ
破滅的忘却 継続学習を続けると、新しいデータの学習によりモデルパラメータが修正され、それにより過去の記憶に関連したパラメータも変更され、重要な過去の情報を忘却してしまう。本研究では過去の代表的なサンプルを残して学習を進める経験リプレイを実施することで性能が向上することを確認した。 元の記事へ
本件に関する問合せ先
国立研究開発法人情報通信研究機構
サイバーセキュリティ研究所
セキュリティ基盤研究室
小川 一人
 ml.nict.go.jp
ml.nict.go.jp国立大学法人神戸大学
数理・データサイエンスセンター
教授 小澤 誠一
kobe-u.ac.jpEAGLYS株式会社
取締役/CSO 丸山 祐丞eaglys.co.jp広報(取材受付)
国立研究開発法人情報通信研究機構
広報部 報道室
nict.go.jp国立大学法人神戸大学
総務部 広報課
office.kobe-u.ac.jpEAGLYS株式会社
eaglys.co.jp